![]()
Google Generative Language Semantic Retriever#
In this notebook, we will show you how to get started quickly with using Google’s Generative Language Semantic Retriever, which offers specialized embedding models for high quality retrieval and a tuned model for producing grounded output with customizable safety settings. We will also show you some advanced examples on how to combine the power of LlamaIndex and this unique offering from Google.
Installation#
%pip install llama-index-llms-gemini
%pip install llama-index-vector-stores-google
%pip install llama-index-indices-managed-google
%pip install llama-index-response-synthesizers-google
%pip install llama-index
%pip install "google-ai-generativelanguage>=0.4,<=1.0"
Google Authentication Overview#
The Google Semantic Retriever API lets you perform semantic search on your own data. Since it’s your data, this needs stricter access controls than API keys. Authenticate with OAuth with service accounts or through your user credentials (example in the bottom of the notebook).
This quickstart uses a simplified authentication approach meant for a testing environment, and service account setup are typically easier to start from. Demo recording for authenticating using service accounts: Demo.
For a production environment, learn about authentication and authorization before choosing the access credentials that are appropriate for your app.
Note: At this time, the Google Generative AI Semantic Retriever API is only available in certain regions.
Setup OAuth using service accounts#
Follow the steps below to setup OAuth using service accounts:
Enable the Generative Language API.
Create the Service Account by following the documentation.
After creating the service account, generate a service account key.
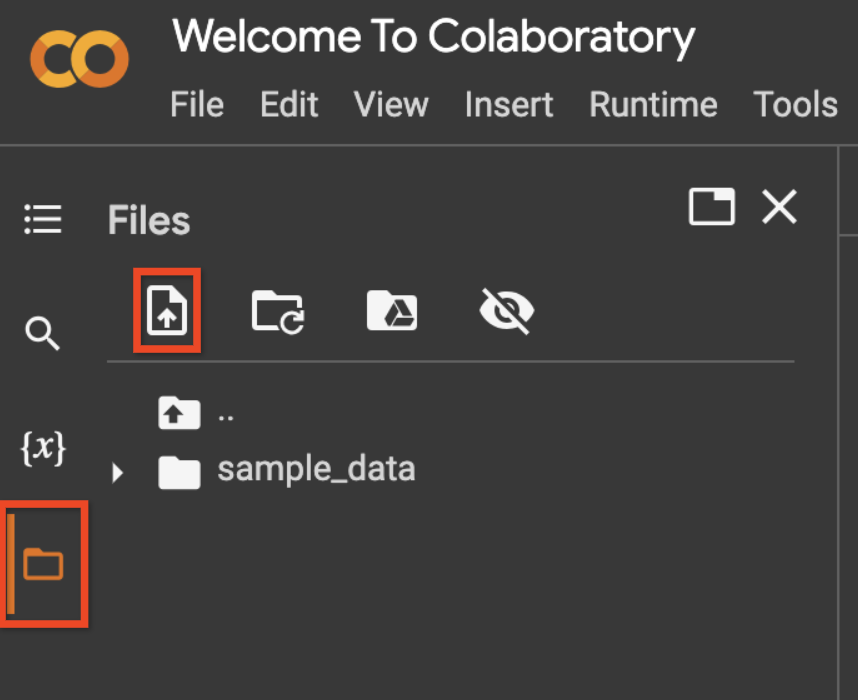
Upload your service account file by using the file icon on the left sidebar, then the upload icon, as shown in the screenshot below.
Rename the uploaded file to
service_account_key.jsonor change the variableservice_account_file_namein the code below.
%pip install google-auth-oauthlib
from google.oauth2 import service_account
from llama_index.vector_stores.google import set_google_config
credentials = service_account.Credentials.from_service_account_file(
"service_account_key.json",
scopes=[
"https://www.googleapis.com/auth/generative-language.retriever",
],
)
set_google_config(auth_credentials=credentials)
Download Data#
!mkdir -p 'data/paul_graham/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'
Setup#
First, let’s create some helper functions behind the scene.
import llama_index.core.vector_stores.google.generativeai.genai_extension as genaix
from typing import Iterable
from random import randrange
LLAMA_INDEX_COLAB_CORPUS_ID_PREFIX = f"llama-index-colab"
SESSION_CORPUS_ID_PREFIX = (
f"{LLAMA_INDEX_COLAB_CORPUS_ID_PREFIX}-{randrange(1000000)}"
)
def corpus_id(num_id: int) -> str:
return f"{SESSION_CORPUS_ID_PREFIX}-{num_id}"
SESSION_CORPUS_ID = corpus_id(1)
def list_corpora() -> Iterable[genaix.Corpus]:
client = genaix.build_semantic_retriever()
yield from genaix.list_corpora(client=client)
def delete_corpus(*, corpus_id: str) -> None:
client = genaix.build_semantic_retriever()
genaix.delete_corpus(corpus_id=corpus_id, client=client)
def cleanup_colab_corpora():
for corpus in list_corpora():
if corpus.corpus_id.startswith(LLAMA_INDEX_COLAB_CORPUS_ID_PREFIX):
try:
delete_corpus(corpus_id=corpus.corpus_id)
print(f"Deleted corpus {corpus.corpus_id}.")
except Exception:
pass
# Remove any previously leftover corpora from this colab.
cleanup_colab_corpora()
Basic Usage#
A corpus is a collection of documents. A document is a body of text that is broken into chunks.
from llama_index.core import SimpleDirectoryReader
from llama_index.indices.managed.google import GoogleIndex
from llama_index.core import Response
import time
# Create a corpus.
index = GoogleIndex.create_corpus(
corpus_id=SESSION_CORPUS_ID, display_name="My first corpus!"
)
print(f"Newly created corpus ID is {index.corpus_id}.")
# Ingestion.
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
index.insert_documents(documents)
Let’s check that what we’ve ingested.
for corpus in list_corpora():
print(corpus)
Let’s ask the index a question.
# Querying.
query_engine = index.as_query_engine()
response = query_engine.query("What did Paul Graham do growing up?")
assert isinstance(response, Response)
# Show response.
print(f"Response is {response.response}")
# Show cited passages that were used to construct the response.
for cited_text in [node.text for node in response.source_nodes]:
print(f"Cited text: {cited_text}")
# Show answerability. 0 means not answerable from the passages.
# 1 means the model is certain the answer can be provided from the passages.
if response.metadata:
print(
f"Answerability: {response.metadata.get('answerable_probability', 0)}"
)
Creating a Corpus#
There are various ways to create a corpus.
# The Google server will provide a corpus ID for you.
index = GoogleIndex.create_corpus(display_name="My first corpus!")
print(index.corpus_id)
# You can also provide your own corpus ID. However, this ID needs to be globally
# unique. You will get an exception if someone else has this ID already.
index = GoogleIndex.create_corpus(
corpus_id="my-first-corpus", display_name="My first corpus!"
)
# If you do not provide any parameter, Google will provide ID and a default
# display name for you.
index = GoogleIndex.create_corpus()
Reusing a Corpus#
Corpora you created persists on the Google servers under your account. You can use its ID to get a handle back. Then, you can query it, add more document to it, etc.
# Use a previously created corpus.
index = GoogleIndex.from_corpus(corpus_id=SESSION_CORPUS_ID)
# Query it again!
query_engine = index.as_query_engine()
response = query_engine.query("Which company did Paul Graham build?")
assert isinstance(response, Response)
# Show response.
print(f"Response is {response.response}")
Listing and Deleting Corpora#
See the Python library google-generativeai for further documentation.
Loading Documents#
Many node parsers and text splitters in LlamaIndex automatically add to each node a source_node to associate it to a file, e.g.
relationships={
NodeRelationship.SOURCE: RelatedNodeInfo(
node_id="abc-123",
metadata={"file_name": "Title for the document"},
)
},
Both GoogleIndex and GoogleVectorStore recognize this source node,
and will automatically create documents under your corpus on the Google servers.
In case you are writing your own chunker, you should supply this source node relationship too like below:
from llama_index.core.schema import NodeRelationship, RelatedNodeInfo, TextNode
index = GoogleIndex.from_corpus(corpus_id=SESSION_CORPUS_ID)
index.insert_nodes(
[
TextNode(
text="It was the best of times.",
relationships={
NodeRelationship.SOURCE: RelatedNodeInfo(
node_id="123",
metadata={"file_name": "Tale of Two Cities"},
)
},
),
TextNode(
text="It was the worst of times.",
relationships={
NodeRelationship.SOURCE: RelatedNodeInfo(
node_id="123",
metadata={"file_name": "Tale of Two Cities"},
)
},
),
TextNode(
text="Bugs Bunny: Wassup doc?",
relationships={
NodeRelationship.SOURCE: RelatedNodeInfo(
node_id="456",
metadata={"file_name": "Bugs Bunny Adventure"},
)
},
),
]
)
If your nodes do not have a source node, then Google server will put your nodes in a default document under your corpus.
Listing and Deleting Documents#
See the Python library google-generativeai for further documentation.
Querying Corpus#
Google’s query engine is backed by a specially tuned LLM that grounds its response based on retrieved passages. For each response, an answerability probability is returned to indicate how confident the LLM was in answering the question from the retrieved passages.
Furthermore, Google’s query engine supports answering styles, such as ABSTRACTIVE (succint but abstract), EXTRACTIVE (very brief and extractive) and VERBOSE (extra details).
The engine also supports safety settings.
from google.ai.generativelanguage import (
GenerateAnswerRequest,
HarmCategory,
SafetySetting,
)
index = GoogleIndex.from_corpus(corpus_id=SESSION_CORPUS_ID)
query_engine = index.as_query_engine(
# We recommend temperature between 0 and 0.2.
temperature=0.2,
# See package `google-generativeai` for other voice styles.
answer_style=GenerateAnswerRequest.AnswerStyle.ABSTRACTIVE,
# See package `google-generativeai` for additional safety settings.
safety_setting=[
SafetySetting(
category=HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
threshold=SafetySetting.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
SafetySetting(
category=HarmCategory.HARM_CATEGORY_VIOLENCE,
threshold=SafetySetting.HarmBlockThreshold.BLOCK_ONLY_HIGH,
),
],
)
response = query_engine.query("What was Bugs Bunny's favorite saying?")
print(response)
See the Python library google-generativeai for further documentation.
Interpreting the Response#
from llama_index.core import Response
response = query_engine.query("What were Paul Graham's achievements?")
assert isinstance(response, Response)
# Show response.
print(f"Response is {response.response}")
# Show cited passages that were used to construct the response.
for cited_text in [node.text for node in response.source_nodes]:
print(f"Cited text: {cited_text}")
# Show answerability. 0 means not answerable from the passages.
# 1 means the model is certain the answer can be provided from the passages.
if response.metadata:
print(
f"Answerability: {response.metadata.get('answerable_probability', 0)}"
)
Advanced RAG#
The GoogleIndex is built based on GoogleVectorStore and GoogleTextSynthesizer.
These components can be combined with other powerful constructs in LlamaIndex to produce advanced RAG applications.
Below we show a few examples.
Setup#
First, you need an API key. Get one from AI Studio.
from llama_index.llms.gemini import Gemini
GEMINI_API_KEY = "" # @param {type:"string"}
gemini = Gemini(api_key=GEMINI_API_KEY)
Reranker + Google Retriever#
Converting content into vectors is a lossy process. LLM-based Reranking remediates this by reranking the retrieved content using LLM, which has higher fidelity because it has access to both the actual query and the passage.
from llama_index.response_synthesizers.google import GoogleTextSynthesizer
from llama_index.vector_stores.google import GoogleVectorStore
from llama_index.core import VectorStoreIndex
from llama_index.core.postprocessor import LLMRerank
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
# Set up the query engine with a reranker.
store = GoogleVectorStore.from_corpus(corpus_id=SESSION_CORPUS_ID)
index = VectorStoreIndex.from_vector_store(
vector_store=store,
)
response_synthesizer = GoogleTextSynthesizer.from_defaults(
temperature=0.2,
answer_style=GenerateAnswerRequest.AnswerStyle.ABSTRACTIVE,
)
reranker = LLMRerank(
top_n=10,
llm=gemini,
)
query_engine = RetrieverQueryEngine.from_args(
retriever=VectorIndexRetriever(
index=index,
similarity_top_k=20,
),
node_postprocessors=[reranker],
response_synthesizer=response_synthesizer,
)
# Query.
response = query_engine.query("What were Paul Graham's achievements?")
print(response)
Multi-Query + Google Retriever#
Sometimes, a user’s query can be too complex. You may get better retrieval result if you break down the original query into smaller, better focused queries.
from llama_index.core.indices.query.query_transform.base import (
StepDecomposeQueryTransform,
)
from llama_index.core.query_engine import MultiStepQueryEngine
# Set up the query engine with multi-turn query-rewriter.
store = GoogleVectorStore.from_corpus(corpus_id=SESSION_CORPUS_ID)
index = VectorStoreIndex.from_vector_store(
vector_store=store,
)
response_synthesizer = GoogleTextSynthesizer.from_defaults(
temperature=0.2,
answer_style=GenerateAnswerRequest.AnswerStyle.ABSTRACTIVE,
)
single_step_query_engine = index.as_query_engine(
similarity_top_k=10,
response_synthesizer=response_synthesizer,
)
step_decompose_transform = StepDecomposeQueryTransform(
llm=gemini,
verbose=True,
)
query_engine = MultiStepQueryEngine(
query_engine=single_step_query_engine,
query_transform=step_decompose_transform,
response_synthesizer=response_synthesizer,
index_summary="Ask me anything.",
num_steps=6,
)
# Query.
response = query_engine.query("What were Paul Graham's achievements?")
print(response)
HyDE + Google Retriever#
When you can write prompt that would produce fake answers that share many traits with the real answer, you can try HyDE!
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine import TransformQueryEngine
# Set up the query engine with multi-turn query-rewriter.
store = GoogleVectorStore.from_corpus(corpus_id=SESSION_CORPUS_ID)
index = VectorStoreIndex.from_vector_store(
vector_store=store,
)
response_synthesizer = GoogleTextSynthesizer.from_defaults(
temperature=0.2,
answer_style=GenerateAnswerRequest.AnswerStyle.ABSTRACTIVE,
)
base_query_engine = index.as_query_engine(
similarity_top_k=10,
response_synthesizer=response_synthesizer,
)
hyde = HyDEQueryTransform(
llm=gemini,
include_original=False,
)
hyde_query_engine = TransformQueryEngine(base_query_engine, hyde)
# Query.
response = query_engine.query("What were Paul Graham's achievements?")
print(response)
Multi-Query + Reranker + HyDE + Google Retriever#
Or combine them all!
# Google's retriever and AQA model setup.
store = GoogleVectorStore.from_corpus(corpus_id=SESSION_CORPUS_ID)
index = VectorStoreIndex.from_vector_store(
vector_store=store,
)
response_synthesizer = GoogleTextSynthesizer.from_defaults(
temperature=0.2, answer_style=GenerateAnswerRequest.AnswerStyle.ABSTRACTIVE
)
# Reranker setup.
reranker = LLMRerank(
top_n=10,
llm=gemini,
)
single_step_query_engine = index.as_query_engine(
similarity_top_k=20,
node_postprocessors=[reranker],
response_synthesizer=response_synthesizer,
)
# HyDE setup.
hyde = HyDEQueryTransform(
llm=gemini,
include_original=False,
)
hyde_query_engine = TransformQueryEngine(single_step_query_engine, hyde)
# Multi-query setup.
step_decompose_transform = StepDecomposeQueryTransform(
llm=gemini, verbose=True
)
query_engine = MultiStepQueryEngine(
query_engine=hyde_query_engine,
query_transform=step_decompose_transform,
response_synthesizer=response_synthesizer,
index_summary="Ask me anything.",
num_steps=6,
)
# Query.
response = query_engine.query("What were Paul Graham's achievements?")
print(response)
Cleanup corpora created in the colab#
cleanup_colab_corpora()
Appendix: Setup OAuth with user credentials#
Please follow OAuth Quickstart to setup OAuth using user credentials. Below are overview of steps from the documentation that are required.
Enable the
Generative Language API: DocumentationConfigure the OAuth consent screen: Documentation
Authorize credentials for a desktop application: Documentation
If you want to run this notebook in Colab start by uploading your
client_secret*.jsonfile using the “File > Upload” option.Rename the uploaded file to
client_secret.jsonor change the variableclient_file_namein the code below.
# Replace TODO-your-project-name with the project used in the OAuth Quickstart
project_name = "TODO-your-project-name" # @param {type:"string"}
# Replace [email protected] with the email added as a test user in the OAuth Quickstart
email = "[email protected]" # @param {type:"string"}
# Replace client_secret.json with the client_secret_* file name you uploaded.
client_file_name = "client_secret.json"
# IMPORTANT: Follow the instructions from the output - you must copy the command
# to your terminal and copy the output after authentication back here.
!gcloud config set project $project_name
!gcloud config set account $email
# NOTE: The simplified project setup in this tutorial triggers a "Google hasn't verified this app." dialog.
# This is normal, click "Advanced" -> "Go to [app name] (unsafe)"
!gcloud auth application-default login --no-browser --client-id-file=$client_file_name --scopes="https://www.googleapis.com/auth/generative-language.retriever,https://www.googleapis.com/auth/cloud-platform"
This will provide you with a URL, which you should enter into your local browser. Follow the instruction to complete the authentication and authorization.